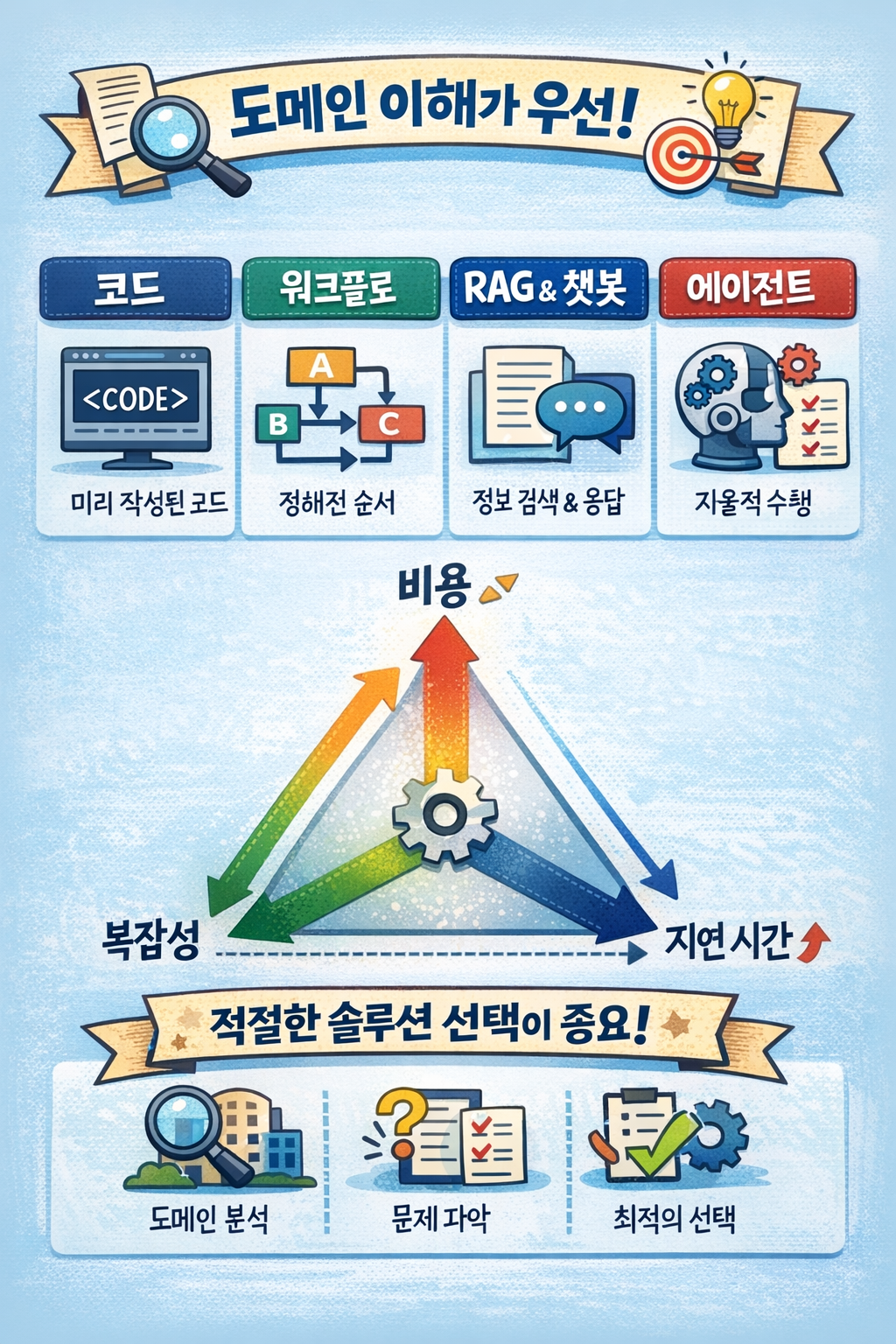
이전 글인 [에이전트를 도입하기 전에 고려사항]에서 말했듯, 코드, 워크플로우, RAG & 챗봇을 고려해도 고객의 문제를 해결하지 못했을 때, 이제 에이전트를 선택해야 한다. 그렇다면, 에이전트 시스템을 설계하려면 어떤 걸 고려해야 할까?
사람이 하는 일을 모사한 에이전트가 있다고 하면, 모델, 도구, 메모리, 지식 베이스인 4가지를 오케스트레이션 하여 사용자에게 답변해 준다. 즉 이 4가지 요소를 잘 설계해야 에이전트 시스템이 된다.

[API와 로컬 모델]
첫 번째인 모델은 크게 API와 로컬로 나눌 수 있다. 로컬에서 오픈소스 모델이나 개발을 하여 Agent를 구성할 수 있다. 하지만, 대부분의 경우는 비용과 시간문제로 자체 모델을 개발하기 어렵다. 그렇기에 클로드나 OpenAI API, Google API로 최신모델을 사용하여 에이전트를 만들게 된다. 하지만 실제 설계는 어떤 모델을 어떤 영역에 잘 배치하고 사용하냐에 따라 비용과 효율성이 결정된다. 쉽게 말해, 단순 인사말을 대답하는데 GPT5.2 모델(작성일 기준 최신) 대신 gpt-4.1-mini나 gpt-4o-mini도 충분하다.
[Reasoning 모델 선택 기준]
그렇다면 어떤 기준으로 모델을 선택할까? 제일 먼저 “생각할 문제”인지 따져봐야 한다. 생각할 문제는 Reasoning 모델이 필요한가를 결정하는 기준을 말한다. 고민해보지 않아도 되는 문제를 굳이 reasoning 모델을 쓸 필요 있는가? gpt-5 계열이 reasoning 모델인데, 단순 텍스트 정리를 이 reasoning 모델로 할 필요 없다. 오히려 하면, 응답지연만 길어지고 비용만 올라간다. 물론 reasoning을 해서 글을 쓴다면 고려해볼 만하다. reasoning 모델 여부를 선택했다면 이제 작은 모델(저비용 모델)부터 적용해서 내가 원하는 결과가 만들어지는지 보고 선택한다. 만약 gpt-5-nano 결과가 마음에 들지 않으면 gpt-5-mini로 교체한다. 또 마음에 들지 않으면 gpt-5, gpt-5.2 다 고려한다. 같은 퀄리티의 답변이라면 저비용이 유리하기에 이렇게 선택한다.
[동일한 모델일 필요는 없어]
여기서 흔히 착각하는 경우가, 모든 컴포넌트(혹은 노드)에 동일한 모델일 필요없다. 여기서 이야기하는 컴포넌트는 한 가지 역할이 부여된 부분이라고 생각하면 편하다. 예를 들어, 오타를 수정한 글을 보고 다시 글을 작성한다고 한다면, 오타를 잡는 노드와 수정한 글을 보고 글을 작성하는 노드는 다른 모델을 선택하면 된다. 다시 말하지만, 정답은 없다. 하지만 같은 결과인데 저비용이면 좋다.
[모델 사용 벨런스]
마지막으로 모델을 선택할 때는 모델 사용 간에 벨런스를 잘 분배해야 한다. OpenAI 기준으로는 각 모델에 limit token과 request rate이 존재한다. 만약 내가 gpt-5만 사용한다면 limit에 걸려 오류가 나게 된다. 물론 token 관리를 통해 지연 응답으로 처리할 수 있지만, gpt-5와 gpt-5.2, gpt-4.1을 고루 분배한다면 3배의 토큰 limit를 사용할 수 있다.
'LLM' 카테고리의 다른 글
| 에이전트을 도입하기 전에 생각할 것들 (0) | 2026.02.24 |
|---|---|
| MHA vs GQA vs MLA vs Sliding Window Attention (1) | 2026.02.01 |
| RAG란? (1) (3) | 2024.12.20 |